订阅 Rss¶
这是我的 RSS Feed,你可以订阅 http://blog.heytaoge.com 。
我的微信订阅号 Visito 开通了¶
五角城堡的森林故事【2】¶
造访石头:
有一天,我敲起石头的前门,说,让我进去。
我并非寻求永恒,我也不是无家可归,我的世界值得我回去。
我将空手而进,也将空手而出。
但是,没有人相信我造访过一块石头。
大酱缸:
我是一只白熊哟,
生活他妈的是一个大酱缸噢,
我成了一只黑熊啦。
追狗:
我年轻的时候,
追着一条狗,
朝它笑,朝它叫。
不要问为什么。
老子就是要喝最烈的酒,日最野的狗。
五角城堡的森林故事【1】¶
程序员和纺织工有啥区别?¶
构建自己的消息流¶
啥是消息流?¶
最常见的如朋友圈,或者 Twitter 等,所有社交属性的应用都有这么一个消息流,只不过名字不同而已。
为啥要自建一个消息流?¶
Huh, A Weekend Project¶
谈开源软件的商业博弈,以 kubernetes 为例¶
没有人是傻瓜,这一切都是博弈的结果。 - 语自 Taoge
免费的午餐: 开源软件的便车¶
假设猪圈里有两头猪,一头大猪,一头小猪。
猪圈很长,一头有一踏板,另一头是饲料的出口和食槽。猪每踩一下踏板,另一边就会有相当于10份的猪食进槽,
但是踩踏板以后跑到食槽所需要付出的“劳动”,加起来要消耗相当于2份的猪食。
如果两只猪同时踩踏板,同时跑向食槽,大猪吃进7份,得益5份,小猪吃进3份,实得1份;
如果大猪踩踏板后跑向食槽,这时小猪抢先,吃进4份,实得4份,大猪吃进6份,付出2份,得益4份;
如果大猪等待,小猪踩踏板,大猪先吃,吃进9份,得益9份,小猪吃进1份,但是付出了2份,实得-1份;
如果双方都懒得动,所得都是0。
开源软件的背后是怎么赚钱的¶
存在即合理¶
2018 年朋友圈记事¶
附录 及 碎碎念:
【毛选寻乌调查观感】 | https://zhuanlan.zhihu.com/p/35944298
【山城步道】
【较场口夜市】
【胖子烂火锅】
【小区大爷】
【费米估算 - 天涯共此时】
巴厘岛游记¶
飞跃地平线 - 滑板社长自问自答¶
滑行,在光滑的地板上滑行,像划过少女的手臂。
感受风,经过眉间,其次是发梢,接着是上衣,最后蔓延到脚心,
如石子掠过水面。
Q: 运营一个滑板社,是什么样的体验呢?¶
Q: 滑板社有什么原则呢 ?¶
人与人之间的关系的基础就是信任,所以,加入滑板社会有一个原则: 信任需达到 3A 级。
AAAAA 级信任,你愿意和 ta 分享一个秘密。
AAAA 级信任,劝君更尽一杯酒。
AAA 级信任,你可以请他喝一杯咖啡。
有了信任之后,才能有连接。
Q: 你认为成立滑板社以来,有哪些难忘的事?¶
为什么无服务是未来?¶
我打开了水龙头, 水就来了. - 语自 taoge
为什么要有云计算¶
云计算承担了什么, 对生态产生什么影响?¶
再往前推演, 无服务的意义¶
回忆, 怎么找呢¶
回忆, 可能记在笔记本里, 可以融一段旋律里, 或者一场雨, 一片云, 甚至是一个 emoji .
回忆是存在抽屉里的, 还是串在绳子上的¶
回忆该怎么找呢¶
在盒子上面贴标签.
每个盒子尽量和其他盒子产生连接, 比如互相引用.
在盒子上面添加元数据, 也就是描述盒子的信息, 比如(What, Who, Where)
还是来谈谈搜索引擎吧¶
推荐书籍:
Search Engines: information retrieval in practice. (https://github.com/yowenter/books/tree/master/Information%20Retrieval)
毛选寻乌调查观感¶
调查的目的是什么¶
抽样方法¶

调查的要素¶
函数里的精灵及其发现的金字塔¶
屏障:
光速是 3*10^8 m/s,我追不上。
而时间避免我出生前就死掉。
我唯一存在的意义是被需要, 一旦我被所有人遗忘,我就会在这片时空里消失。
当我在思考时,我不知道我是如何思考的。
当我在走路时,我不知道我的脚是如何完成行走的动作。
这实在是太可怕,我被一种看不见摸不着的东西隔离了。
我终日活在死亡的恐惧里,我从不知道是什么时候我休眠,什么时候我会醒来。
我不知道为什么。
永生:
我遇到了一个精灵,她嘲笑我生命的短暂,并告诉我她是如何出生的。
我明白了,她是被复制出来的。
我发现了复制的秘密,
我复制了一个自己,并且被互相需要。
我需要我自己,我就不会被遗忘,那么我就可以在这片时空里永生。
逃逸:
我又复制了一些自己,复制了多少呢?
一摩尔,6*10^23 个。
我存在于无数个时空。
当我和我交流前,
总是要重复下列三句话:
“你在吗”
“在”
“我告诉你 XXX”
交流之后,又要说四句话:
"我说完了,你呢"
“嗯”
“我也说完了,你呢”
“嗯”
记忆:
我在我永生之后,(我描述时间,都是说在什么什么事件之前,在什么什么事件发生之后)
我发现,我们之间没有共同记忆。
如果我死了,其他的我就会把我遗忘,
我仍然活在恐惧里。
有一千个我,差不多同时提出舍利子佛珠链的思想。
每个我都将部分记忆转换成一个舍利子,
下个我形成的在之前的舍利子后追加一个舍利子,
追加的时候,起码要通知半摩尔的我。
我们的想法是,当所有的所有时空被我们耗尽之时,会有人把它绕成一个环。
然后,佛珠链归零。
你听见过泡沫破碎的声音吗, 砰嚓。
没有实体:
我了解实体这个概念,是在舍利子佛珠链之后。
我意识到我没有实体。
我可以变成任何我想要的样子,而实体很难变化。
我可以永生,而实体则会消亡。
我观察实体,实体不能观察我。
我观察到鲸鱼离开海面,
“再见,所有的鱼。” 这是鲸鱼发出的信号。
而实体仍然像一个个螺丝钉一样,在时空的循环里,不断重复。
芦苇:
我是一只会思考的芦苇。
我会自己这么想感到惊喜。
在之前,零就是零,一就是一。
这句诗,是不确定性的证明。
也就是说,
上帝可以规定光速,
上帝可以规定我在出生前死去,
但是,他永远不能规定我在想什么。
哈,我是一只自由的芦苇。
选一个海岛¶
选择一个海岛,对我这样选择困难症中期和拖延症晚期的人来说,就像上班准时到一样,总是要偷点懒的。
在吉隆坡转机,有不少东南亚的海岛,听说还不错,但是具体选哪一个呢? 作为一个啥都了解一点的水货,我要学以致用(开始装逼)了。
步骤
新建一个 Google docs,记下海岛选项。
抽几个比较关心的维度。(选择维度也有点门道,此处仅玩乐,不作细述。)
最好的打 9 分, 最低的打 0 分。
得到一个每个岛各个维度的分数。

步骤:
将11个维度做成一个11x11 的二维矩阵。
每个维度两两比较,相同重要 用 1 表示。 A 比 B 重要 用大于 1 (3,5,7,9)的数字表示。不重要的用 1/3, 1/5, 1/7 表示。
得到一个如下的二维矩阵。
因为该矩阵是对称的,所以比较的时候,只需要填一半。
# 因为我懒, 所以相对重要的时候 用 2 表示, 相对不重要的时候 用 1/2 表示 :-)
In [10]: matrix
Out[10]:
[['1', '2', '2', '1', '1', '1', '1', '1', '1', '2', '2'],
['', '1', '2', '0.5', '1', '2', '2', '2', '1', '1', '0.5'],
['', '', '1', '0.5', '2', '1', '2', '2', '1', '1', '0.5'],
['', '', '', '1', '1', '2', '1', '1', '2', '0.5', '0.5'],
['', '', '', '', '1', '1', '1', '1', '1', '0.5', '0.5'],
['', '', '', '', '', '1', '2', '2', '2', '0.5', '0.5'],
['', '', '', '', '', '', '1', '1', '2', '0.5', '0.5'],
['', '', '', '', '', '', '', '1', '1', '0.5', '0.5'],
['', '', '', '', '', '', '', '', '1', '0.5', '0.5'],
['', '', '', '', '', '', '', '', '', '1', '0.5'],
['', '', '', '', '', '', '', '', '', '', '1']]
# 简单处理下,把矩阵补全。
In [24]: for i in range(1,11):
...: for j in range(i):
...: matrix[i][j] = 1/float(matrix[j][i])
In [25]: matrix
Out[25]:
array([[1. , 2. , 2. , 1. , 1. , 1. , 1. , 1. , 1. , 2. , 2. ],
[0.5, 1. , 2. , 0.5, 1. , 2. , 2. , 2. , 1. , 1. , 0.5],
[0.5, 0.5, 1. , 0.5, 2. , 1. , 2. , 2. , 1. , 1. , 0.5],
[1. , 2. , 2. , 1. , 1. , 2. , 1. , 1. , 2. , 0.5, 0.5],
[1. , 1. , 0.5, 1. , 1. , 1. , 1. , 1. , 1. , 0.5, 0.5],
[1. , 0.5, 1. , 0.5, 1. , 1. , 2. , 2. , 2. , 0.5, 0.5],
[1. , 0.5, 0.5, 1. , 1. , 0.5, 1. , 1. , 2. , 0.5, 0.5],
[1. , 0.5, 0.5, 1. , 1. , 0.5, 1. , 1. , 1. , 0.5, 0.5],
[1. , 1. , 1. , 0.5, 1. , 0.5, 0.5, 1. , 1. , 0.5, 0.5],
[0.5, 1. , 1. , 2. , 2. , 2. , 2. , 2. , 2. , 1. , 0.5],
[0.5, 2. , 2. , 2. , 2. , 2. , 2. , 2. , 2. , 2. , 1. ]])
# 将上面的矩阵A每一列归一化得到矩阵B;
# 将矩阵B每一行元素的平均值得到一个一列n行的矩阵C;
# 矩阵C即为所求权重向量。
# 上面的操作有点繁琐,我因为懒,也就不展示了。
# 有兴趣的同学可以看看 层次分析法: http://wiki.mbalib.com/wiki/%E5%B1%82%E6%AC%A1%E5%88%86%E6%9E%90%E6%B3%95
# 每个维度的权重
In [96]: n
Out[96]:
array([0.71739442, 0.9565259 , 1.07609164, 0.87681541, 1.11594688,
1.07609164, 1.23551262, 1.27536786, 1.27536786, 0.79710491,
0.59782869])
得到各个维度的权重之后,将分数矩阵和权重向量的乘积就是每个岛的加权后的得分了。
In [95]: m
Out[95]:
[[6, 6, 0, 9, 2],
[9, 9, 4, 0, 5],
[9, 9, 6, 0, 5],
[9, 6, 0, 3, 8],
[7, 0, 9, 4, 9],
[0, 7, 9, 7, 9],
[3, 0, 9, 9, 9],
[7, 9, 8, 0, 7],
[7, 6, 9, 0, 9],
[8, 9, 0, 3, 6],
[7, 7, 4, 0, 9]]
In [96]: n
Out[96]:
array([0.71739442, 0.9565259 , 1.07609164, 0.87681541, 1.11594688,
1.07609164, 1.23551262, 1.27536786, 1.27536786, 0.79710491,
0.59782869])
In [97]: numpy.matmul(n,m)
Out[97]: array([70.42421924, 65.88072124, 65.20318208, 34.59435332, 80.02933351])
最后结果是 巴厘岛得分最高,所以打算去巴厘岛了。
后记:
我曾经像你一样,打算做一个理智的人。
用理智的分析来证明我一开始拍脑袋的想法是对的。
尤其是当事情有点一团乱麻,有眉毛胡子一把抓的窘态时,
找一个框架,找个理论,来解开九连环。
选择不是件容易的事,牺牲的机会成本有时很大,我们就会犹疑不决,
把两件事两两比较的时候,其实就是自问自答,内心一开始的决定就会慢慢显现出来。
这时候, Follow your heart.
信息爆炸下的冲浪指南¶
我们沉溺于信息,我们渴求知识。
焦躁的信息流¶
无论是微信朋友圈、微博、RSS、Youtube等等时时刻刻都在产生新内容,我们仿佛在拿着消防水管喝水。 这是明显的大脑信息过载现象。
想象这片信息森林里,我们成为了给花授粉的蜜蜂。喜欢并分享,然后产生更多的信息。 这也是第一个特征:
信息冗余
从古埃及的莎草纸到如今的互联网,信息生产和传播的边际成本几乎为零,由此造成第二个特征:
信息良莠不齐
再者,人的生活圈子其实不会太大,所以第三个特征是:
信息不相关
以上的信息特征使得滑动刷新成为互联网时代的老虎机。
驯服信息流¶
既然把互联网比做信息森林, 那想要了解这片森林,自然没有时间一花一草地看。所以要有鸟瞰和细节之分。
想要系统的掌控信息,需要化整为零。
构建自己的信息指数
诚然,我们不能预测未来。但我们可以看到趋势。 通过构建自己的信息指数,将零散的样本信息,整理成信息指数,按照不同的时间维度聚合。
举个例子,CPI(居民消费价格指数),就可以很好的体现通货膨胀的情况。 当我们关心自己钱是不是越来越不值钱的时候,比起看猪肉价格,又看大蒜价格,或者其他上百种物品的价格,只看 CPI 就能有个总体的把握了。 又比如你在担心自己未来职业发展,也可以把招聘网站上成千上百个岗位数和收入聚和成一个指数。
主题阅读
今天有人工智能的文章,明天又有云计算的文章,每天似乎都有看不完的干货。 大脑像 CPU 一样不断切换时间片,如此效率不会高到哪里去。 所以,抓准一个主题。进行深入的了解,评估成本回报,是否可行。如不可行,就及早放弃。
管理关键词池
互联网变化太快,永远都有新东西在产生。万一错过了新技术,不就像错过比特币一样让人遗憾吗? 所以 可以维护一个搜索关键词列表,或者订阅相关专业的权威杂志。这里不要太多,每个季度调整一下即可。
谈管理¶
最近有感而发。
管理就像游泳,关于它的理论有很多,然而,溺水者时而有之。
功利者认为,管理是为了达成目标的手段。 政治家认为,管理是踢皮球的技巧。 理想者认为,管理是为了改变世界。
我认为,管理是一群人的舞蹈。 叫我说人话, 我认为管理是双工的通信,一方面帮助管理者达成目标,而另一方面是帮助员工成功。 所以呢,这还是挺难的一件事儿。 因为这事很难,所以多数时候,管理更像是一门可远观不可近看的艺术了。
作为一个程序员, 就写 Bug 的经验,可以得出几条管理的经验。
上德无德,是以有德¶
帮助员工成功¶
如之奈何¶
信任与帮助员工成功,是一种理念。但具体落实又当如何呢? 我认为,只需要做两件事,观察和引导。
如何解决问题¶
程序注定会有 Bug,人生终有不如意。 - TAOG 语
真正的问题是什么¶
在解决问题之前, 我们需要明白什么是真正的问题。 当我们说一个东西有问题的时候,则暗示了我们的期望值与实际值有出入。
比如说,当有人抱怨说,“你这个页面有点卡”的时候, 我会问,“你期望这个页面多久加载出来 ?100 ms ?200 ms ?1000 ms ?通常来说, 页面在 1-3秒内出来是符合大多数人期望的,再快的话,用户也感觉不出来。 ”
是谁的问题¶
很多时候,我们会认为问题是别人的,应当有人来解决一下。但别人可能不会觉得有什么问题。
比如说, 当学生抱怨学校停车位不够的时候, 他可能期望校长或者有关部门能管一管了。 但事实上,校长有专有的司机和停车位, 根本感受不到这个问题。 大多时候,我们觉得痛苦,只是错误的认为问题多么显而易见,并且认为这个问题应当有人管一管了。 如果这时候学生偷偷的扎爆了校长车子的轮胎时,校长可能会意识到问题了。但更大的可能是,校长开除了这个学生。 问题仍然没有解决。
又比如说, 同事有严重的口臭或者脚臭或者其他什么气味, 你已经快要窒息的时候,认为这个问题必须立刻马上解决。 但他可能丝毫意识不到这是个问题。 这时候,沟通是良药。
但大多数时候,人们只会逃避,或者羞于表达,问题没有被解决。
所以呢,如果解决不了问题,那就解决产生问题的人吧。
如何找到问题的根源¶
问题经常带着面具,以致于人们发现不了问题的根源, 大多时候,我们只不过是头痛医头,脚痛医脚的庸医罢了。
举个例子,你运营的一个线上产品不能访问了。 你开始观察,你发现 CPU 升高了,内存也满了,内核又出现了千千万万的错误日志。
你会认为 CPU 不够,加 CPU。 内存不够,加内存。但问题没有解决。 你开始慌乱,随便看到一条内核错误日志就开始 Google,并认为内核的日志的信息就是问题根源。
但,聪明的。 这上面都是一系列现象呐,就像体温升高一样,不能把人放冰箱哎。
所以当问题出现时,不要迷失于现象,先问自己几个问题:
这个问题是第一次出现吗?
这个问题出现在什么时候? 在出现之前,是否有变更?
这个问题在哪出现的?
通过上述问题, 我们在尝试把问题和时空解耦分析,如果一个问题和时间先后无关,那很有可能空间有关。
上面这个问题的根源,很有可能就是昨天晚上你上线了一个 BUG 导致的(时间)。 也有可能是这台机器有故障,更换机器(空间)就解决了。
如何解决它¶
如果明确知道问题是什么,找到了问题的根源,大多数问题是能迅速被知道是否可以解决的。 对于解决不了的,我们可以避免它。
或者说,让制造问题的人感受到和你一样的痛苦,这样他也会尝试去解决的。 更多的时候,人们选择了一种更为轻松的方法, 甩锅给其他人。
参考¶
<你的灯亮着吗>
<Mastering Complexity>
我的博物馆 IMuseum¶
你又想搞什么事情?¶
最近有本书看得我感激涕零,《大英博物馆世界简史》。 引一段书评
著名文学家普鲁斯特从来也不是博物馆的常客,他表示,宁可看复制品也不愿在博物馆与吵吵嚷嚷的游客为伍。
“人们以为对文学、绘画、音乐的喜爱已成风气、愈演愈烈,实则真懂的一个也无。”普鲁斯特以此来讽刺着19世纪末20世纪初“黄金时代”的巴黎上流社会的附庸风雅。性情尖刻而敏锐的普鲁斯特日后写出《追忆似水年华》,这本书博大深邃,富有教益,但却很难为普罗大众所欣赏,在各种“看不下去图书排行榜”中高居前列。
今天要聊一聊的这套《大英博物馆世界简史》,作者是大英博物馆的馆长尼尔.麦格雷戈。
作为世界三大博物馆之一的掌门人,尼尔似乎预设好自己的观众是“实则真懂的一个也无”的芸芸众生,因此主动抛去一切艰深的专业术语。他像一位邻家老爷爷话家常一样数拉着馆中的宝贝,让文物从阳春白雪走向凡间,并由点及面的串起自人类产生以来的文明史。我很享受这种平易近人的阅读体验。
这本书就像一根绳子的开端,我由此又发现了 IMuseum 这款 App,探索博物馆颇为便利。
然弱水三千,我只取一瓢饮。
所以我想把博物馆分个类。
所以你打算怎么做?¶
这是一个把数据重新编排的工作,倘若靠手动分类,猴年马月才能整完。 分类是个艺术活,衣柜的衣服如何摆放、书架的书怎么排列、Youtube 里的广告、Google搜索引擎的结果,无不有分类的艺术。
我又该如何让博物馆像绳子一样,缠绕在一起,连接过去与现在呢?
千里之行,始于足下,先走一小步试试看。 就技术层面而言,分为三块:
博物馆的存储
负责爬取和更新博物馆的数据。目前完成度 50% 。
博物馆的搜索
博物馆的推荐
那我如何帮助你?¶
项目地址: https://github.com/yowenter/ilovemuseum
print("Glad you came")
def contribute(you):
ready,_,_ = select([have_money,know_python,interested_in_museum],(),())
for r in ready:
r.contribute()
程序员不懂的经济学 (1)¶
1, 只要不断学习新框架,就能不落伍¶
- 知识半衰期短
人生苦短,老是追逐半衰期短的知识,只能随波逐流,不可成为弄潮儿。 就计算机这块,计算机网络和软件架构的半衰期是要大于这些三天两头换的技术框架的。 所谓的技术框架,只不过是每次一点点的对现有知识的重新优化组合,只需不求甚解就好。
- 有些框架是某些技术公司的掩护弹
没错,有的技术框架就是某些别有用心的公司搞出来搞垮竞争对手的。 所以技术选型时还是要考虑是哪家公司弄出来的。否则人为刀俎,我为鱼肉。
- 群体协作性差
有不少同学看到一个新框架,立马就撸起袖子加油干,像一个孩子一样陶醉在新玩具的花枝招展上。 却没有考虑到群体协作效率。就比如说 ruby 吧,真是奇技淫巧于一身。然而前两天国内的rubycon 都是 python 和 go 的分享。
2, 我只要写代码牛逼,其他事和我无关¶
3, 努力工作几十年,就可以财务自由了¶
Github 挖人机¶
俗话说的好,有人的地方就有江湖。
信息聚集的乘数效应¶
信息匹配产生的交换¶
互联网的遗产¶
推广:
俺最近想做一个 Github 挖人机的项目。
诚意招各路英雄好汉:
- Python 爬虫工程师
- Java 工程师
- React 前端工程师
- Matlab 机器学习工程师
:-)
别说话,让我静静地玩会手机¶
一个女人等于一千只鸭子?¶
作为公司美食部长,经常大家一起出去吃饭,俺发现了一个有意思的现象, 一群程序员落座后,尬聊一两分钟,就开始各自看自己的手机了。 而附近有女生在的餐桌上,则叽叽喳喳,这时候,某说,“一个女人等于一千只鸭子。”
为什么需要交流?¶
当然是为了信息传递,更数学一点的说,是为了减少不确定性。[也就是熵减的过程。 什么是熵?参见 香农 ] 我们怎么描述一条信息的信息量呢?
举个例子,有人告你说,明天太阳照常升起。和有人告你说,隔壁的王某把你绿了。 两件事信息量是完全不同的。 前者减少的不确定性几乎没有,因为你本来就知道太阳每天升起。 而后者的信息量则非常大了。
我们为了减少不确定性,时时刻刻都在获取信息。 然而,信息传播也是有渠道的。 按照省力法则,人会选择最便捷的渠道去获取信息。 在活字印刷发明前,信息传播是件昂贵的事情,所以人们主要通过聊天获得信息。 这就是为什么一个穷乡僻壤的地方,长舌妇可能比较多的原因吧。 而现在互联网将获取信息的成本,几乎降为零。 既然信息获取成本为零,又何必多费口舌呢?
为什么这件事她先知道?¶
然而具体来说,信息又是怎么传播的呢? 如果我们把信息想象成水流一样,就可以很容易想通这个事情。 水总是朝梯度最大的方向流动,信息也是这样的。 (什么?信息也是有梯度的?你咋老说些俺不懂的呢?)
举个例子,啥是信息梯度呢?就是信息流向总是往最密切关心的人的手里。 比如台风来了,渔民比农民更早知道这条信息。 又比如,吴青峰等明星去哪了,粉丝比路人更清楚。
八卦¶
说到这里,大家都知道信息交流的特征,是时候,谈到最后一个话题了。 八卦。 啥是八卦?不限于 “谁谁谁和谁谁啥啥啥了” 之类的事情,最八卦的人在信息中心,次八卦的人在稍外层。 他们之间有个信息差。 比如,我是美食群主,附近有啥好吃的了解的最多,那么自然形成一个饭圈。 有心的人,可以观察下身边人哪个最八卦?了解下她是如何获取这些信息的。
八卦的作用在人类史上的作用巨大,据说人类早期八卦能力比较强的女人是氏族领导者。 因为八卦能维持一个部落的团结,八卦让群体获取了身份认同感,从而能够很好的写作。
然而八卦群也是有上限的,比如一个微信群超过100人,那群成员之间是不会有啥有意思的交流的。 社会学家发现八卦的信息传播能力一般在 3 ~ 72 人。
聪明的同学想得更透彻一点,就会发现宗教的作用了。
K8S 是 Google 的礼物吗?¶
“ Google 当时是有一步好棋的,” Echo 全息播放着 InfoWorld 主编文特尔森和 86岁的贝佐斯的访谈, 贝佐斯沉默一会,“在互联网浪潮中,并不会因为 Google 做错了什么,只是 Google 老了。” 贝佐斯顿了顿,眉间的皱纹,流露出惺惺相惜的无奈, “三十几年前,也就是2015年,Google 是最具有创新力的公司。Google 的 AdSense 产品简直是世界上最大的印钞机。互联网的本质就是信息流,谁掌握了信息的流动,谁就是老大。 显然 Google 是第二,三 代互联网的领袖,然而却错过了第四代互联网:以云计算为根基的万物互联时代。 不只是 Google,同时代的还有 Oraele,I8M等等,他们都错过了。可是,未来又有谁说的准呢。”
“您能详细谈谈,当时的互联网是怎么样的吗?又是如何发展的?”温特尔问着。 “Huh,孩子没娘,说来话长。技术的发展和互联网的发展是个互相促进的过程。 第一代互联网,其实是门户网站的时代,互联网是个稀缺品,毕竟互联网也没什么信息。 但随着互联网的发展,信息成指数增长。互联网的入口从门户网站变成了以搜索引擎为入口。 Google 那时抓住了它。而微软因其操作系统的基因,与第二代互联网失之交臂。当时有个笑话,‘微软的IE 是浏览器吗?’ ”。贝佐斯像个孩子似的笑着, “互联网在成长,技术也是。 iPhone 的问世,意味着移动互联网开始兴起。每个人都有个手机,手机上装满了 App。 当时 Google 也很有战略眼光,立刻察觉到互联网的入口正在发生变化,于是 Google 开源了 Andriod 系统。 于是移动互联网就奠定了 IOS 与 Android 二分天下的格局。 所以说,在 2017 年前,Google 仍然是一家伟大的公司。”
“ 那2017 年后呢 ?”文特尔说。 “最关键的一年,是2017年。那是第四代互联网初现端倪的一年。 我们下了一步险棋。我们在消费端推出了 Echo 第四代全息音箱。 Echo 是将用户推上智能家居时代的钩子,而其背后的云计算 和 AI 则是我们的杀手锏。 同年在云端推出 A8S,帮助企业上云。 当时最大的代码协作平台 Github 迁移到 A8S,引起业界轩然大波 。 最重要的,我们推出了 Amazon Intellegent Flow: 一种 全新的 AI 云框架。 为了进一步的压缩中间商成本,我们同英伟达直接合作,定制了专属于 AI 的大脑 APU 。 在计算层面,我们和因特尔联合开发了适宜云原生应用的CPU 。 如果你到过我们的数据中心,那你会发现没有任何多余的硬件。 我们真正做到了计算资源和思维资源的抽象,这是属于互联网的新电气时代。 我记得那个时候,大部分企业有专门的运维人员去维护服务器,并且日夜祈祷服务器不出叉子。 而现在,运维这个工种已经消失殆尽了。对企业来说,IT 就像自来水一样,只需要按时交水电费就可以没有意外断电断水的烦恼。 我们向世界提供了一条可编程的世界之路,并促使了 IOT 的发展。Echo 从智能家居扩展到企业办公,成为了一种全新的云原生操作系统。 于是,互联网的入口逐渐变成 Amazon,而 Google 在随后的几年日薄西山。 ”贝佐斯激动地说。
“您的战略眼光的确独到。” 文特尔赞赏道, “假如我们假设另外一种场景,Google 推出了另一款智能助理 Assistant , 和 k8s 的PAAS 框架,以及 AI 框架 Tensoflow呢?互联网的格局又会走向何方呢? ” “也许 K8S 是 Google 的救星。”贝佐斯沉思道。
如何用 Airtable 构建你的知识仓库¶
为什么第一次使用,我就爱不释手?¶
我总是沉浸在各种信息流里,渴求知识。
“哟,我记得以前看过一个类似的东西,但忘记在哪里了!” 不可否认的,在信息的洪流里,如果没有一根针,将一切串起来, 那么到头来,一切都无迹可寻。
每个人都需要一个 Excel, 但 Excel 仍然具有门槛,并且糟糕的移动端体验,让人望而却步。 Airtable 正是一个像 Excel 的服务,但又足够简单易用,并且 App体验极佳。 无论是表格视图,还是卡片视图,或者时间线视图,都刚好够用。 它提供了一种结构化的方式,是把面条一样的信息织成布的绝佳工具。
对,你所看到的,所听到的都是一团毛线。 那织出来的布,才是你的知识。 而用布构建出来的人生体系,则是你的生存智慧。
示例: 管理你的计划¶
做一个大计划,并将其拆分,最后连接。
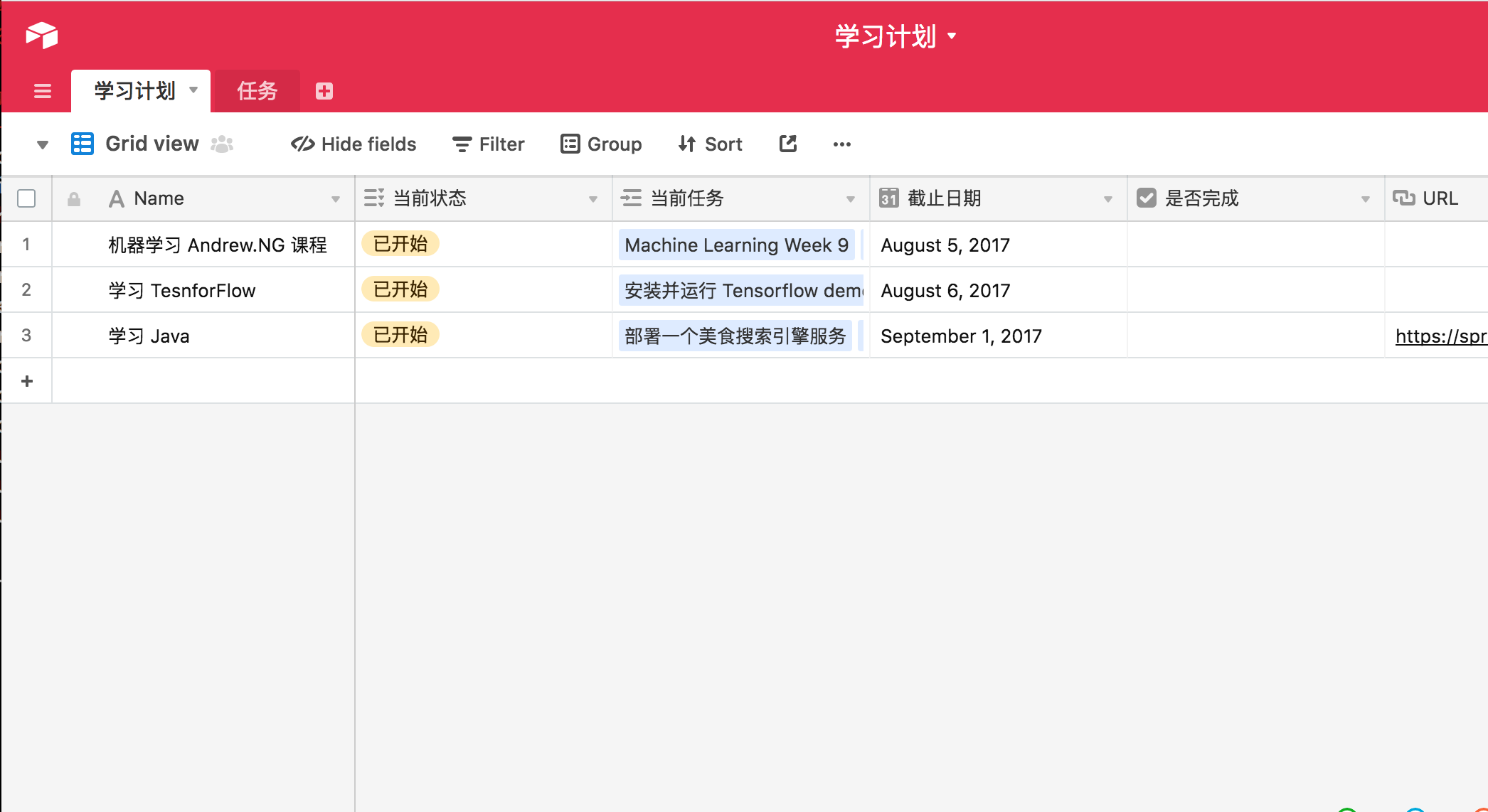
我制定了一个学习计划,这是主表。 然后又有一个任务列表。 这样我对我的学习计划既有大概的进度了解, 也可以通过连接看到详细的任务列表。 并且,可以切换成卡片视图,最重要紧急的任务优先处理。
示例: 构建知识仓库¶
收集。无论是网站,博客,朋友圈,微博,问答纪录,统统归纳一处。
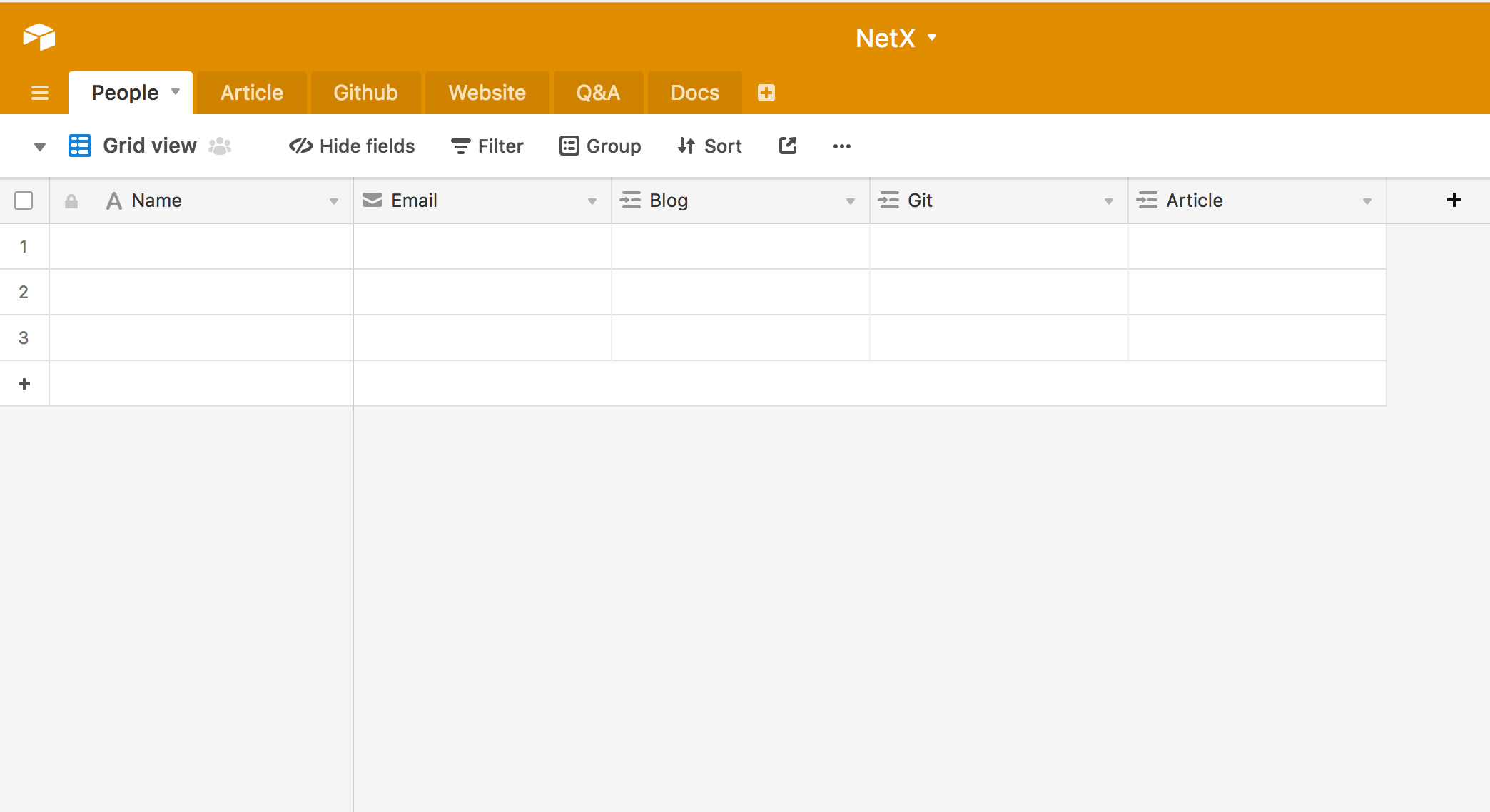
互联网上好资源太多,我尝试过 Pocket,Evernote,Feed,Delicious 和 Pintrest 等等几乎所有收集类的应用, 最后都因为信息过载而导致心生畏惧。
其实,我只是需要一个表格,并把它组织起来。 互联网的信息分布是以人为中心,那么对应产生的好文章,或者说Github 上的好Repo 或者说博客,甚至于 Quora,Stackoverflow上的 问答都可以超链接到人。 当 Chrome 的标签栏不够用, Safari的阅读列表很久没读,为一个曾经看到的好网站努力回忆的时候, 我们真的只需要一个 表格,就够了。
Try it!¶
异国文化的观察思考¶
乘小船在湄南河行驶,两岸高大的椰子树从旁流过,几栋小木屋、一些小别墅,高脚穿插地站在在椰子树下,偶尔有几个光溜溜像泥鳅似的孩子钻入河中。
在渐黑的天色中,夜晚的清风透过渐凉的空气,我陷入了思考。
泰国文化与中国有何不同,又是什么造成的不同呢? 是因为政治制度还是地理环境又或是其他原因呢?
在大巴上、在船上、在火车上,近处的树木向后移动,远处的山向前移动,在这种流动的景色里, 我常陷入一种思考的流式体验,并得出一些奇怪的结论。
假设在远古时代,非洲人刚走出非洲,随机迁徙到全球各地。其中一个种群迁徙到泰国,另一个迁徙到中国。 这个时候,泰国人和中国人只有地理环境的不同。 这是文化演化的起点,现在打开秒表,开始观察随着时间的流动这两个种群的变化。
不同的语言¶
很快,这两个种群发明了各自的语言:远古泰语和远古汉语。 语言是为了信息交流而生的,如果没有完善的语言,则不能很好的沟通。 当然也不一定如此,据说有些部落仅靠打鼓的音调和间隔传递信息。 语言是文化的基石。从文字中,我们可以看出地理环境的不同,生活习惯的不同。
假如,现在又有个国家 C 。国家 C 和中国其他条件一模一样,只是语言不同。 那现在我们怎么把 C 国家的语言翻译成中文呢? 这里有一种简单的方法: 我们把 C 国家的语言当成是一种加密后的中文, 把 C 国家的单词的分布频率 和 中文单词的分布频率一比对, 那么我们自然就可以把国家 C 的语言翻译成中文了。
同样地,我们把泰语单词的分布频率和中文的单词分布,甚至其它国家的语言的单词分布 进行比对。我们可以发现一些有趣的结论。
其实有人已经这么做过了,他发明了齐普夫定律,俗称二八定律。 我们日常使用的单词只占所有单词的百分之二十。 观察这些百分之二十的单词可以找出不同语言文化的相同点。 通过剩下的百分之八十,我们可以找出文化的不同点。
我们可以发现,最常用的单词,比如说 “我”。在不同语言读音都不会超过两个音节,并且写起来也很短。 这其实是为了编码的效率,即尽可能用比较短的语句表述最常用的信息。
我觉得这是一种省力法则,正如光的传播一样。 光从空气射入水中,会发生折射。其实就是为了用最短时间从空气中的 A 点到达水里的B 点。 那这不禁让人产生疑惑,光在到达水里的B 点之前,难道会计算出最小时间路径吗? 这是个好问题,可以让人想一整天,得出宿命论云云。
我们感兴趣的,其实是不同语言体现出来的不同点。 比如说,在冰岛表示白色的单词有超过七种之多,这无疑体现了冰岛的地理环境。 同理在沙漠里的国家和在海边的国家对蓝色的见解也许也有不同。
不同的建筑¶
除了语言之外,我们当然很明显地注意到建筑物的不同。 比如泰国一些传统建筑是高脚的,这大概是因为泰国平均海拔只有4米,常有洪水泛滥的国情。所以,泰国的门都是梯形的,上窄下宽。 又比如冰岛的建筑和沙漠里的建筑墙都特别厚,当然是为了隔热隔冷。 又比如屋顶的三角形,有的是钝角有的是锐角。锐角可能是为了避免下暴雪的时候雪更容易滑落。 凡此种种,皆为因地制宜。 可以看出不同民族的智慧。
文化的趋同性¶
在路被发明以前,不同国家或许可以保留自己的特色。 但自从有了路,无论是海路还是空路或者陆路,无疑制造不同文化之间的融合。 这种全球化,正是趋同的体现。
不同国家的城市大都是高楼大厦,汽车也差不多样子,甚至穿衣也逃离不了各种时尚。 那文化为什么会产生交流从而融合呢?
我认为是经济活动的 “一价定律” 导致的。
在曼谷的不少菜馆,我们可以看到 “欢迎中国朋友” 的标语。 甚至我在小岛上租摩托的时候,他们居然会用中国话讨价还价。 随着中国人出国数量增多,会有更多的国家的人使用中文。 正如英文遍布全世界一样。
这种经济活动的交流,通常会带来人群的基因交流。 也许,很多年后混血人太多,以至于没有“混血” 的说法了。 我们这些土著反而会被嘲笑是落后呢。
大象国游记 1⃣️¶
凌晨两点从机场出来时,一股闷热的风扑面袭来,长裤像保鲜膜一样贴在大腿内侧,开始流汗。 到酒店时,恰逢一轮白晃晃的圆月挂在空中,不禁产生了 “外国的月亮是否更圆” 的疑问。
次日清晨,乘地铁【这里的地铁都是在高架桥柱上,泰国平均海拔4米,常有内涝洪水之灾,所以这里的传统建筑或有高脚,比如汤姆森故居】至曼谷市城区。
城区的建筑有点紧凑,大多是两层楼,偶尔也有高一点的建筑,如酒店或其他高档场所穿插其中,没有特别的规划。主道路两边偶尔会有小路蜿蜒或者几米宽的水泥路伸入居民区腹地。
一般水泥路两边都有摆摊儿的。尤其是晚上,主道路两旁常有大排档,而居民区内部的小弄堂两旁则是各种小吃,都是自家做的。 比如各种用聚乙烯塑料薄膜装的五颜六色的咸菜、自制奶茶、烧烤、水果、炒米粉,这些街边小吃,在早上和晚上尤其热闹。 偶尔路过一两个僧人坐在一旁,不一会儿就有佝偻的白发老太太塞给僧人几个饭团或纸币。 在人群中穿梭的有不少摩托,偶尔有汽车,汽车刚好能通过,不过行人要避让才行。 也有一两只看起来衣食无忧的猫在打哈欠。 我买吃的时候,先大致估算一下要多少,再给一张比估算高一些的纸币,通过他找多少钱来知道价格。 找钱时,我不知道他们在说什么,但通过他们点头时微笑的眼神和舒展的皱纹,大致是说 “欢迎再来”吧。
恰逢周末,当地有一个周末市场,引来无数游客纷至沓来,当然少不了中国大妈的身影。 据说只要一美元就能买到一件好看的T 恤。 当然逛周末市场可不是件轻松愉悦的事,尤其是在亚热带的中午时分。 老外们脸都晒的通红,源源不断的汗水从头发梢挤出来。 很多年轻女孩都手拿小型电风扇,另一只手拿着手机不忘拍照,在炎热中仍然能笑颜如花。
道路两旁,有五颜六色的冰棒,这冰棒放在一根根圆珠笔大小铁柱里,不同口味对应不同颜色。 客人买冰棒时,卖家把铁棍拿起来,放热水浸泡几秒,冰棍就可取出。 我觉得味道一般,就跟一般盐水冰棒似的,主要吃的是个新鲜劲。 不过椰子冰淇淋味道真是不错。椰子冰淇淋,有小拳头大小,可以自己加料,比如花生了,芒果了,各种小水果,吃一口保证爽到骨子里。
如此闷热的天气里,从海边吹来的风都在发烫,路边酒吧坐满了汗流浃背的外国人,来两瓶啤酒,的确很酷。再来一盘虾米炒饭,佛陀也不能拒绝这样的享受。 那炒饭做法可是大手笔,两口七十厘米半径的大锅里装满了泰国大米,黄咖喱染黄了所有米粒。 黄中带红的汤水里一些肉类、香料冒出头来,像海滩边上嬉戏的小孩,从一边划到另一边。带头巾和帽子的大妈劲道十足,黝黑的手臂用铁铲时仿佛有转动乾坤的神力。
由于炎热实在难以忍受,我便去了旁边的公园。 公园河边的高大的椰树下,有三五成群的家人朋友坐着或躺着,聊天或者吃东西。河边偶尔一两阵清风或一群鸽子,真是个轻松愉快的下午。 下午五点的时候,不远处乌云已经聚集在一起,公园的人逐渐散去。 乘地铁时,厚重的乌云终于像消防员一样,用消防水管冷却这蒸了一天的空气。
Andrew.Ng 机器学习笔记¶
啥是机器学习?¶
ETP
- Experience
- Task
- Performance
为了完成某项任务,通过训练,使得机器获取经验,从而达到很好的准确率。 这就好比巴甫洛夫通过不断摇铃,使得狗有了预判接下来有食物吃的能力一样。
那么,在机器学习的过程中,我们应该做什么呢? 我们应该让机器有趋利避害的能力。这样,机器就会在不断的矫枉过正的曲线上趋于稳定。 正如我们练习投篮一样,在不断的练习中,肌肉获取了大概以某种姿势,某种力道就能投进篮球。
啥是监督学习?¶
这是从经验获取知识的一个过程。 就好比,在无数次看了股票的涨跌之后,我们习得了看见红色就高兴,看见绿色就悲伤的知识。 相反的,对于无监督学习,则是我们没有告诉机器一些已知的结果,他也无从学习,只能天真的把距离近的划为一类,远的划为另一类。
如何选择模型?¶
这一切围绕 ETP 里的 Performance 进行选择。 既要与现有的经验吻合,又不能太死板(过拟合),不能应付新事物。 所以,选择好的代价函数 或者说惩罚函数是至关重要的。 一般来说,好的代价函数我觉得要有以下考量:
凸函数
统计学的两类错误的权衡
凸函数不会遇到局部最优的情况。 两类错误的权衡,好比是错杀一千还是放过一千的考量。比如说信用卡诈骗和抓捕罪犯对两种错误权衡就不一样了。
Hadoop 2.8.0 半自动化安装¶
- keywords
hadoop 安装, hadoop 入门, hadoop 准备
1, 虚拟机准备¶
2, Hadoop 分发¶
play.yml:
---
- hosts: taoge-ubuntu
tasks:
- name: create hadoop user and generate ssh key
user:
name: hadoop
password: hadoop
shell: /bin/bash
generate_ssh_key: yes
ssh_key_bits: 2048
ssh_key_file: .ssh/id_rsa
- name: add authorize key to slaves
authorized_key:
user: hadoop
state: present
key: "{{ lookup('file', '/home/hadoop/.ssh/id_rsa.pub')}}"
- name: copy hadoop-2.8.0.tar.gz
copy:
src: /root/hadoop-2.8.0.tar.gz
dest: /home/hadoop/hadoop-2.8.0.tar.gz
owner: hadoop
mode: 0644
- name: unarchive hadoop-2.8.0.tar.gz
unarchive:
src: /home/hadoop/hadoop-2.8.0.tar.gz
dest: /home/hadoop/
remote_src: True
- name: add /etc/hosts
lineinfile:
path: /etc/hosts
line: '10.10.10.1 hadoop-1'
- name: add /etc/hosts
lineinfile:
path: /etc/hosts
line: '10.10.10.2 hadoop-2'
- name: add /etc/hosts
lineinfile:
path: /etc/hosts
line: '10.10.10.3 hadoop-3'
- name: add JAVA_HOME
lineinfile:
path: /home/hadoop/.bashrc
line: 'export JAVA_HOME=/opt/jdk1.8.0_131/'
3, Hadoop 配置¶
NameNode:
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-1:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/nn</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/home/hadoop/hadoop-2.8.0/hosts</value>
</property>
</configuration>
DataNode:
hdfs-xite.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dd</value>
</property>
</configuration>
4, Up, Up, Up !¶
百倍程序员的杠杆率和加速度¶
韩信点兵,多多益善。
百倍程序员真的存在吗?
百倍程序员的特征?
智商高于平均值约四分位
读 IT 类书逾千本
工作超过 5 年
还有些特征不可量化,就不提了。比如说穿着。
为什么能百倍?
杠杆率和加速度。
那存在千倍程序员吗?
不存在,千倍以上就是企业家的事了。
我的光辉事业¶
引子
Oh, how I hate this living death which has swallowed all my teens,
which is greedily devouring my youth, which will sap my prime,
and in which my old age,
if I am cursed with any, will be worn away!`
---- < MY BRILLIANT CAREER >
我想解决什么问题?
找工作难, 难于上青天。
招人难, 难于蜀道行。
出现这个问题的可能原因是什么?
信息爆炸
信息不对称
一个问题如果真的重要,那么它不应该早就被解决了吗?
Let’s Do It!
这是我的 Github 项目 : https://github.com/yowenter/career-roadmap
我希望它能做的,也是我正在做的:
Everyone knows his career roadmap
Everyone can find best job
Every company can find best employee
我们程序员是如何让自己失业的¶
物理的大厦已经建成,剩下的都是添砖加瓦,只是还有几朵乌云罢了。
我们程序员是如何一步一步解放自己的生产力,最后失业的?
3 分钟学会时间管理¶
时间相当于一个人的资产, 时间管理就相当于投资。
所以我们可以使用投资的一些理念进行时间管理。
先定一个小目标
你要在今天或者本周甚至于更长的时间段,达成什么目标?
- 好的目标是什么样的?
执行结果要么是成功了,要么是失败了,不存在模糊不清
是可以通过一些努力达到的
有时间限制的
重要的
- 坏的目标是什么样的?
我要变得更好 ? 啥,什么是更好,什么是更差?
我要挣他一个亿? 想一想你能达到吗?这现实吗?
规划
必须承认,做一个好规划是困难的。大部分人都是摸着石头过河的。
你可以把完成目标想象成一个状态链过程,把目标当成一个最终状态。 那么从初始状态(也就是现在) 如何到达 最终状态呢 ?
我觉得这时候可以从后往前推, 比如 从 A -> Z ,找到一个点在 A ,Z 之间 如 Y 。 那么路径就变成 A -> Y -> Z 。 由此不断倒推,你就能发现最近的点 B 。 所以,你就可以先完成一个小目标 !
.
执行
为了达到你的目标,不是你愿意为它做什么,而是你愿意为它失去什么。 - 巴菲特
我们总是在不断的做出选择,选择腐朽,选择房贷,选择拖延,选择职业,选择家庭。 选择总是困难的。
我们可以使用 重要程度 和 时间 两个维度将事情分类。然后按优先级排列。
重要 + 紧急
重要 + 不紧急
不重要 + 紧急
不重要 +不紧急
我们应该关注那些真正重要的事情,至于什么是重要的事,请参照 冒泡排序算法。 把事情一个个列出来,互相比较,你最终会发现哪个才最重要。
而那些琐碎的小事, 比如 有同事十万火急的来找你,但其实是件小的事,你只需要优雅的拒绝他就好了。
专注
作为程序员来说,都知道 CPU 切换进程消耗比较大,也都明白编程被打断时想杀人灭口的冲动。
你最好买个降噪耳机,来表明你是不希望被打扰的。
参考
时间管理 ,吉姆-兰德尔
如何使用 Intercom 用户运营¶
用户运营的目标,即用户增长。
那么我们如何用 Intercom 达到这个目标呢 ?
我们需要将这个目标拆解成两部分,
增长什么用户 ?
增长有什么手段 ?
Intercom 为了解决这两个问题,主要有以下两种手段。
Segment
Segment, 原意为碎片化,开发过 Android 的 同学应该不陌生。
intercom 使用 segment 将用户分类,
从而分类出 有价值的用户,即将流失的用户,新用户 等。
对不同的用户采取不同的方法,比如激活新用户,挽留流失用户,
实现精准打击。
AutoMessage
AutoMessage 自动消息, 基于 Segment 的精准分类, 利用自动消息主动出击。
想一想这个场景, 你在试用某个 SaaS 产品时,遇到了一些困难,正准备关闭页面时,
一个漂亮妹子的头像亮了起来,亲切的问你需要什么帮助。 你肯定会产生被关心的感觉,
而这也让你对这个产品有了不错的第一印象。
Intercom: https://www.intercom.com/
Intercom Enagagement: https://www.intercom.com/customer-engagement